

Summary
- Modern technology is largely built on sight & vision. Our conceptual understanding of smell is terrible by comparison. However, virtually all organisms communicate and coordinate by chemical signals (smells) and very few by light, creating a mismatch between what we know and what is useful to know for bioengineering.
- This conceptual/modeling gap poses a major barrier to bioengineering specifically in cellular, soil, and deep ocean environments, due to their lack of light. Several avenues to close this gap are discussed, ultimately, to scale in-silico models which could be used for verification of designs for cell signaling.
- A device concept for a sensor with superhuman smell is outlined, with an emphasis on projected unit costs and applications in food allergy mitigation.
Background
For all of human technological development, our focus has been nearly exclusively on interacting with our visual surroundings. Our brains are wired to take in massive amounts of information through our eyes, so it was natural for us to design our machines to do the same, which has revolutionized our way of life. Cameras, screens, written language, and conveyed images are ubiquitous in the modern world. But most of the biological world doesn’t interact by sight or light, but by smell. At the small scale, objects are too small, fragile or in a medium that is too dense to see, rendering solar-wavelength optics useless and shorter wavelengths harmful. Even Feynman’s famous lecture proclaiming “There’s plenty of room at the bottom”, is constructed using examples to see, write, and build very tiny things in a mechanical fashion (and he resorted to electron microscopes, which are confined to environments incompatible with life). But what if that’s all wrong?
Although light dominates the length scales from millimeters and larger, much of our vision of the future is powered by biology on the nanoscale or in the dark completely – soil, oceans, and our immune systems interact largely without vision. The biggest problems facing our society today are not problems that can be solved by seeing things. To achieve our goals in this domain we need more control over worlds which are not readily measured visually; if we are to achieve a deep understanding of the tiny living world everything is made up of, we need to learn more about smell.
This isn’t a completely new idea: many in biotechnology have tried to develop a better sense of smell in the past, typically with semiconductor-based sensors. As Elliot Hershberg pointed out in his recent history of Illumina, the DNA sequencing giant, the use of microarrays for sequencing clusters was potentially inspired by the work of David Walt on “artificial noses”. His idea was that fluorescent molecules could non-specifically interact with organic vapors and change their optical properties, back in the ‘90s. More recently, Nathan Lewis, a professor at Caltech, has worked on a similar application. Nathan’s lab website lists a caption which succinctly summarizes the concept of a smell-based sensor: ”An array of broadly-cross reactive sensors in which each individual sensor responds to a variety of odors, but the pattern of differential responses across the array produces a unique pattern for each odorant.” There are also several corporate ventures which use cross-reactive measurements in broadscale identification of biomolecules, including Enveda Biosciences for metabolites and Nautilus Biotechnology for proteins. Although broadscale identification of biomolecules would enable research at unprecedented scale, it’s only the first step – we need to know how the molecules interact, not just what they are. To make an analogy to the semiconductor industry, these companies and others working on the quantification of complex biological mixtures are building the metrology tools of bioengineering – the capacity to verify what is manufactured. And once we can verify circuits, then we can start learning how to design them in earnest.
How to develop better simulation
To design biological machines, we need to be able to model their operation – which in addition to intra-cellular processes such as transcriptional regulation and replication, also means we need to understand how cells are interacting. These components aren’t exchanging bits but rather exchanging scents, which is important to how we try to model or predict their behavior. To describe this further, we look at how we quantify smells; what kind of mathematical object is a smell? Secondly, how do organisms build internal representations of smell and use smell; can we mimic that in our models? Lastly, what are the physics behind smells, and what fundamental processes do we need to better understand to enable biosignal engineering?
Data Representation & Architecture
To quantify smells, there ought to be some sort of mapping between signals and receptors, and perhaps a continuous value to indicate the strength of the interaction between them. There is a many-to-many relationship between signals and receptors. It sounds like a graph (of the nodes and edges kind) might be suitable to describe smells. In fact, it turns out that graphs were first used to describe chemical structure (a closely related topic) anyways, so perhaps we’re on to something there [1]. Sometimes this giant graph of smells and their relationships is referred to as an “interact-ome” or a protein-protein interaction network.
It seems to be too naive to attempt to measure all or even most of the possible binding interactions between receptors and stimuli and explore this network manually or via automation. One approach to characterize this network is to build a model to extrapolate from available observations, for example via deep learning. In a lecture for the Simons Institute, Open AI’s Ilya Sutskever recently discussed how we can conceptualize unsupervised learning performance as a form of data compression [2]. It would seem that there is a very high degree of compression possible between our structural datasets and the graph of molecular interactions, which we can quantify. To be more specific, AlphaFold currently publishes the known structures of 542,378 proteins in 26,935 MB or on average approximately 330 bits per protein structure. Therefore, from a structural perspective, our message might take 330 bits to encode. Let’s model signaling to an E coli bacterium, with 5 transmembrane chemoreceptors. Perhaps each has something like 10 bits worth of response, representing different states it can adopt depending on the signal – this would be the decoded message. 330 bits of “compressed” structure producing 50 bits of potential message tells us the process of decoding the signal likely discards a lot of data.
Therefore, AlphaFold structures, in the context of cellular signaling, could be compressed much further if all we care about is the response they elicit in a simple model organism. The task would then be: can we use unsupervised learning to generate structures from a smaller input space, and try to apply that learning (compression) to map from the compressed input to a receptor response?
Of course, we can also use supervised learning, taking the few interactions we have measured and training against those. This year there have been several demonstrations combining both of these approaches to great effect, achieving over 90% accuracy in human protein-protein binding prediction, which is the first step to decoding cellular signals [3,4].
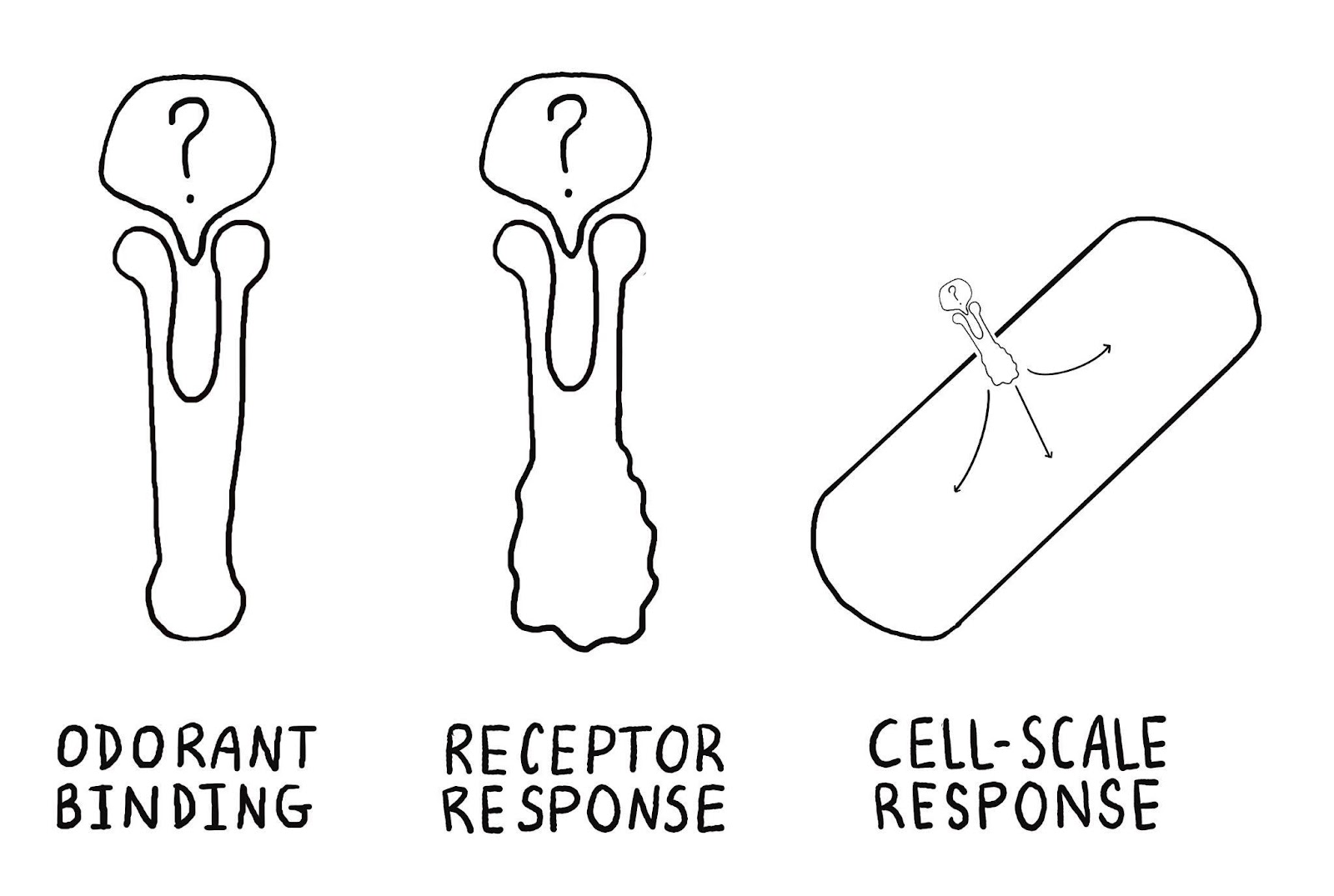
We would then need to also predict the state of the receptor upon binding, and then response of the organism to that state change, if any, to fully predict the interactions of multiple organisms. It is unclear whether these PPI models will generalize to these other steps cross-species signaling, but we might be optimistic since steps 2 and 3 are also largely mediated by protein binding.
Biological Mimicry
In addition to our model architectures, effort ought to be spent better understanding how real organisms process smells. This would potentially unlock a large dataset of available records on the internet: human-recorded smells. If we’re lucky, the regressed sense of human smell will simplify its study – perhaps leading us to a complete description of human olfaction sooner than we might think [5]. Although we could try directly using this data as-is for unsupervised learning,, based on the challenges and subsequent successes of PPI prediction needing an “all-of-the-above” kind of approach we likely need some better understanding of the cognition of smell as well. But it could be fruitful to try anyways; I’m not currently aware of any effort in this area. For example, trying to use meal/recipe recommender systems to identify common smells between food items, or descriptions of scents from material safety data sheets. These data would then be used to predict how human olfactory receptors might bind to odorants.
At an even smaller scale than human olfaction, understanding signaling networks inside single cells can also contribute. To accomplish robust bioengineering, we’re going to need to diagnose cellular problems in addition . For simple processes like chemotaxis in bacteria, we can map out the receptors and ligands which participate in the “decision” to rotate or swim forwards. With such a map, we can engineer behavior, for example, directing the diffusion of bacteria. Although this system of molecular logic used to carry out this behavior (canonically, the “two-component system”) is very common in bacteria, it’s not really seen in animals. Why? Some researchers suspect it could be due to cross-talk (complexity of overall system needs) or persistence (more on this later). In any case, it would seem very helpful to understand these tradeoffs so we can better engineer our biological systems. One of the hardest parts about creating biological machines is that it is expensive to iterate, so we should learn as much as we can from all the iteration in nature.
Physical mechanisms
Not only is the biological basis of smell under-explored, but the physical mechanisms of chemical signaling could prove fruitful as well. A physical description of smells can either help us model them directly or through techniques such as physics-based deep learning. Two key physical qualities of a signal’s transmission are its mobility and persistence.
Regarding mobility, we have studied fluid dynamics for centuries and are beginning to be able to describe the crowded environment of cells. We already build elaborate machinery at the appropriate length scale (microfluidics, microarrays, to semiconductor etching & doping), relying on a fairly detailed description of diffusion in a wide variety of media. Frankly, I think we’re doing pretty well in our understanding of the mobility of smells. No recommendation here other than we should use what we know already — to build an efficient sensor or signal, one key step will be to model analyte transport in the relevant medium. It’s not trivial to do by any means, but the technical know-how is already out there. It’s also possible to learn empirically if needed. One of my favorite reviews on this topic for transport in flow cells is attached [6].
Persistence, on the other hand, is relatively poorly understood. In graduate school, I used to make some protein complexes. They were stored at -20C in glycerol after purification and protease inactivation. But still, after some months, the complex would degrade irreversibly – it could not be reassembled. There were no obvious cleavage products, and it was stored in the dark. If we knew how it was degrading; perhaps we could extend its shelf life? What does it degrade into, and do those problems affect my experiment? One application of this issue is pharmacokinetics — understanding how medicinal molecules are metabolized. Analogously, signaling molecules could be unchanged, enhanced, or inhibited in their function during the degradation process, but we don’t know at the outset. We could try to define degradation in terms of how a protein’s various connections in the interaction network are affected. This would give us the most possible insight into the degradation process. This is a key element of the physical behavior of signals and especially relevant for bioengineering, since the system response will be tied to the lifetime or the signal itself. Simply, if we are to engineer signals in a future green economy, we need to understand their transmission and decay. We want the future to be green, not make us feel green [7]. But before we can produce a complete theory of cell signaling, are there any useful devices we can engineer?
Artificial noses for peanut allergy
The ability to sense biocompounds in complex mixtures can produce a sensor whose applications could be as diverse as the digital camera is today. How expensive might it be to produce a useful warning device for consumer health, essentially a more specific version of an air quality sensor?
Peanut allergies are the most common food allergy, with an estimated cost of about $25,000 per person over an 80 year lifetime in the US associated with either emergency room visits or available acute intervention treatment (i.e. an EpiPen) [8]. Approximately 1 in 1000 people will experience an adverse reaction due to peanut allergy, with incidence increasing significantly over the past several decades. According to one survey, caregivers of children with food allergies would typically be willing to pay 3500 dollars for complete treatment which would enable their child to eat without consideration for allergy risk [9]. There is not currently any such treatment available. As acute intervention (an injection) is costly and stressful, presumably caregivers and children would prefer to avoid exposure, and their responses agree – indirect costs of patients seeking avoidance totals around 1 billion dollars annually in the US.
All this is to say, if there was an inexpensive and effective way to avoid peanuts, there may be a significant market for that, and peanuts only account for about 30% of food allergies. How would we construct a sensor to detect peanuts? Using our principle of biological mimicry, let’s see if an artificial dog nose is up to the task. Trained dogs can detect organic material reliably in fractions of 1 part per million and in the presence of a wide variety of confounding smells [10,11]. Qualitatively, dogs can also be trained to detect allergens and alert on that smell, so if we can reproduce a dog’s capacity to detect peanuts (at approximately 1 part per million in food, or a tiny fraction of a peanut in a meal), that would be useful. A dog’s nose is made up of roughly 100 cm^2 of receptor area containing 300 million receptor cells. This means that the receptors have a mean distance of 6um between them. Importantly, these receptor cells consist of only a limited number of olfactory proteins, produced by hundreds of olfactory genes [12].
Therefore, a simplified version of a dog’s nose will be constructed from a couple thousand patterned microsensors, one microsensor for each olfactory protein. It is assumed that the receptor proteins are working independently and can be engineered to bind at similar affinities to odorants as in vivo. For ease of use, the microsensors should be packed onto a sensor with surface area not exceeding 10 square centimeters, so that the sensor (perhaps made of 3 stacked wafers, each 2×2 cm) could be potentially worn. That means that each microsensor will have approximately 100 square microns of area, so that the total number of protein receptors is similar to the canine model. The purpose of the microsensor is to provide an analog, time-resolved signal of the ions released by an associated ion channel during the receptor binding.
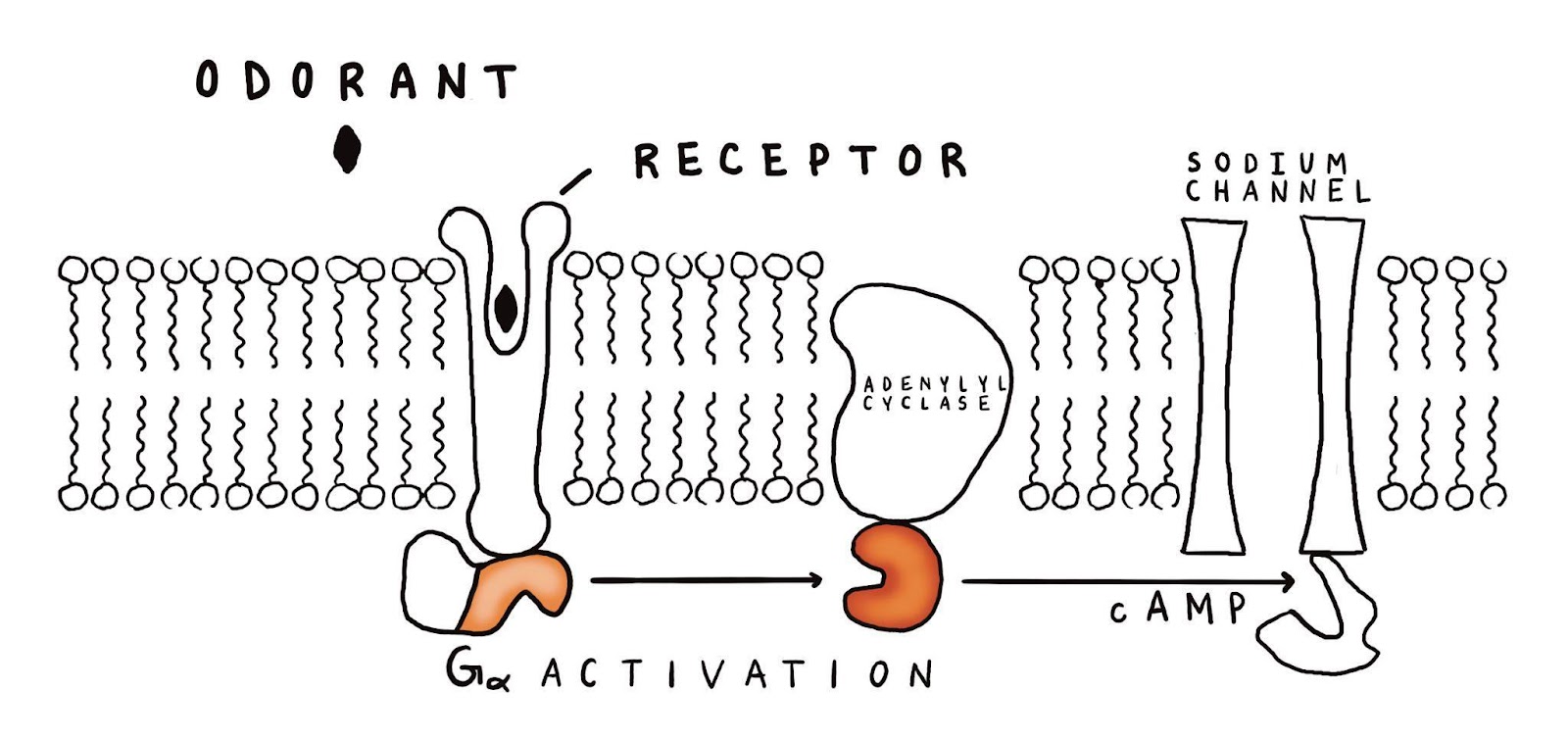
Such a microsensor could be made of an ion-sensitive field effect transistor (ISFET), or potentially with a miniaturized conductivity sensor. Either way, we’re going to need a continuous supply of salty liquid to pass over the surface of the sensor to trap odorants and provide ions for transport when something successful is detected. We also might require either a supply of sensor flushing solution or a fourth protein, a sodium ion pump, to slowly shuttle sodium ions back to the top side of the sensor. Let’s say that each sensor requires ten thousand copies of each of these three or four components packed on to its 100 square microns of area. This would give each copy about 10000 square nanometers of room to breathe – a total density of approximately 10%. Not trivial, but especially if these proteins can be attached to one another, I think it’s fairly reasonable, as it is several orders of magnitude less dense than how they exist on cell membranes.
Unit costs per artificial nose
These specialty proteins would all need to be produced: perhaps several thousand kinds. This would be an impressive scale of protein expression rivaling a large pharmaceutical company today, but each sensor would require only perhaps a few hundred thousand copies to populate it, after accounting for yield losses. Therefore, 1 milligram of each protein would be enough to create millions to billions of devices. Of course, there are manufacturing challenges with working with this concept – either thousands of unique sensors laden with proteins have to be assembled onto a circuit board, endangering the proteins, or miniscule volumes of proteins have to be loaded on fully assembled devices: thousands of such dispenses for every single device. An inkjet printing device could potentially dispense pico-liter scale droplets of micromolar protein to meet the estimated hundred-thousand copies of protein deposited on each chip, but this would be the equivalent of printing several thousand unique colors simultaneously. Protein expression would therefore largely be a fixed cost – at scaled cost of perhaps a thousand dollars per protein to get a milligram of each, it might take 10 million dollars to express all the receptors, putting the unit costs per device somewhere between 10 and 100 dollars depending on volume.
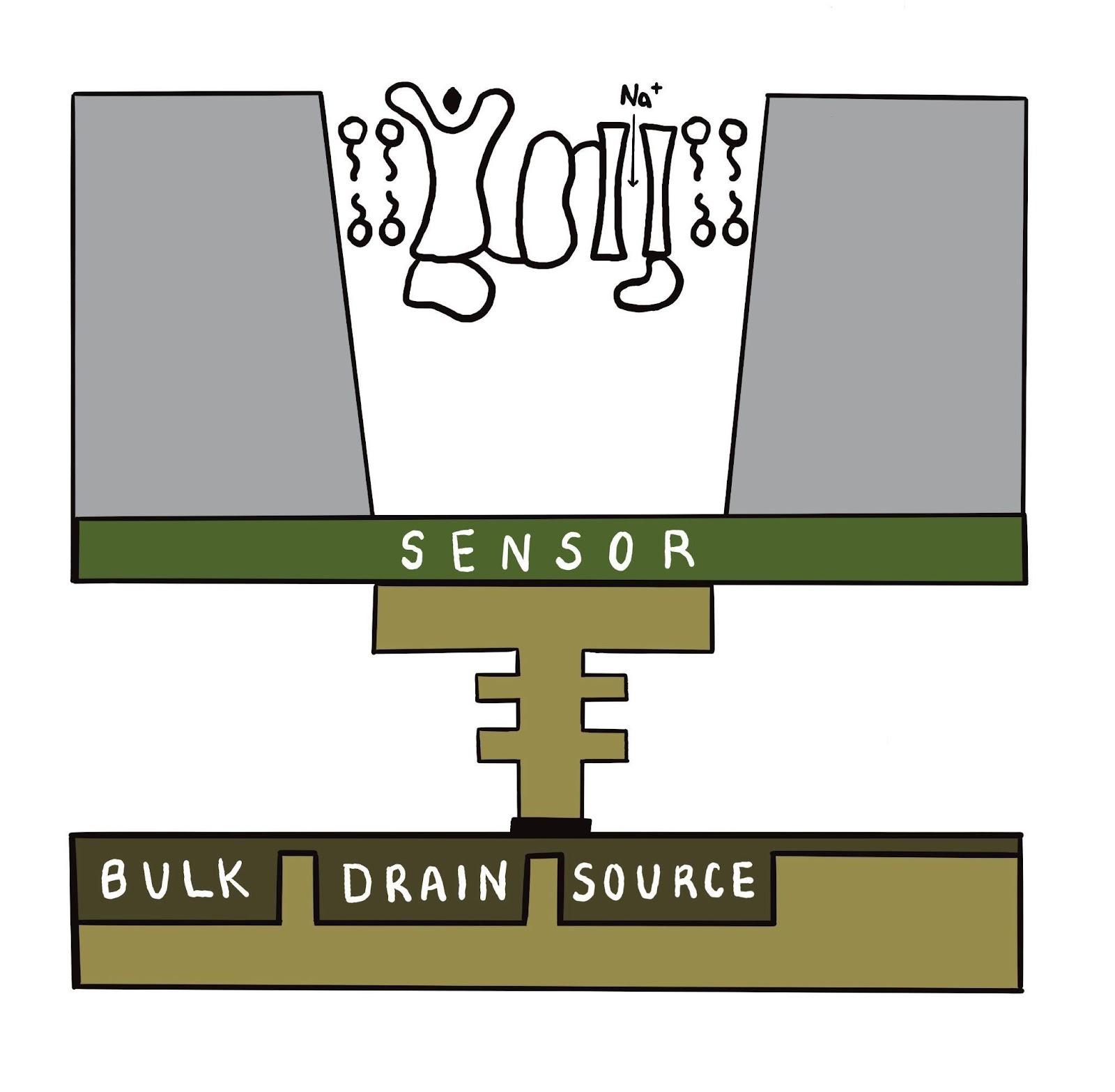
In addition to the protein, the silicon device, similar to an Ion Torrent sequencing flowcell, would need to be fabricated. The Ion Torrent device has millions of ISFET sensors, but we would need far fewer. Based on the cost of an 8-pack of these chips currently (a few thousand dollars), with some significant margin for consumables profit, I’m hopeful we can pattern and produce our chips at unit cost of about 100 dollars each. Adding in another 100 dollars per unit for packaging, assembly, reagent (your nose runs on mucus, and this would require something similar circulating), microfluidics to circulate reagent very slowly, and signal processing, we get something like 300 dollars per unit for volumes of thousands of units, with lots of improvement at higher volume.
This is more than 10 times less than the willingness to pay to resolve the peanut allergy entirely – although it doesn’t meet this need, people are already incurring a thousand dollars in indirect costs per patient per year in other avoidance mitigations such as moving schools or changing jobs – presumably keeping their current job or child’s current school for the same amount of cost could be a preferable outcome due to external factors for many caregivers. Of course, the main challenge in producing this technology is not the size of the benefit it would bring per unit cost, but the large number of technological hurdles to manufacture such a device. Creating and depositing a couple thousand proteins could be an enormous challenge, but the parallel work seems much more likely to be carried out by industry than academia. The enormous challenge also represents an enormous potential moat to competitors.
The same device could be competent for a dizzying array of applications, given how many things a real dog nose can distinguish. Forensics, explosives and disease surveillance, food and water quality are all potential applications. Done right, the only difference isn’t the hardware but only the signal processing — it only takes one set of receptors to smell everything.
Conclusions and next steps
Health is perhaps the most immediate application for highly advanced biosignaling technology. But what about other important challenges that we face, like global warming or food production? One aspect of global warming which is essential is that the producers of global warming (humans) are self-replicating. We exhume resources from the earth at ever greater rates and catabolize it into tiny molecules which end up absorbing things in our atmosphere. I don’t know if smell technology can fix capitalism. But it can help create a sustainable, self-replicating ecosystem to do carbon drawdown on a large scale. The only “scalable solutions” (in capitalism) to draw down carbon involve self-replicating systems, because they have to keep pace with consumption (us), which is self-replicating. The problem is that the only self-replicating thing we understand at scale is monocultures. Experiments with carbon vaults of seaweed, plankton, or bio-oil from pyrolysis have shown it’s possible to sequester carbon back into the ground, but if we are going to be able to actually pull it out of the sky (which is the hard part), you have to grow a lot of stuff. Maintaining massive, energy intensive monocultures is risky and unsustainable [14]. The impacts to local ecosystems can be extreme; monocultures crowd out other species, and the cost of isolating massive monocultures from their predators is similarly damaging (i.e. pesticides, herbicides). A natural solution to this is to take inspiration from gentler forms of agriculture which maintain a diverse & robust ecosystem in place.
Keeping the ecosystem highly productive is much easier if you can monitor and transmit messages between the organisms as they grow. A recent review [15] highlights how important the local living community is for rice yields, a staple crop for more than half of humanity. Yields were often affected by 20-50% across many potential signal sources. Understanding macronutrient content and organism abundance are tasks that smell is well suited towards, especially in a dark and diffusive environment like soil. A huge amount of focus in agri-science is trying to leverage satellite imagery and computer vision to better predict crop yields, but it seems clear that satellites are not the right way to try and study nutrient gradients in soil, they’re trying to see a smell.
Smell technology, although clearly the most direct and well-conserved interaction mode in biology, has been radically under-appreciated for centuries. With recent advances in applied graph theory (AI), sensing, neuroscience, and proteomics, we’re closer than ever before to taking our first steps towards engineering smells and their receptors. But it’s hardly a focus or a guidestone for investors or innovators, and big technical challenges remain. There’s a lot of potentially exciting technology both in the near and long term and it would only take a few breakthroughs to really open the floodgates on smell, many of which are potentially well suited to industrial research. Some of those breakthroughs may be even made possible by a small but committed team. It starts by rethinking what the best tool is for the job – instead of visualizing success, let’s smell and taste it instead.
Limitations & Disclaimers
There are a few important, very basic reasons why humans have focused on optical technology rather than native cell-signaling molecules. Molecules are expensive and photons are cheap. Molecules also have spatial extent, interact with their environment, and travel very slowly by comparison to light or electrical signals.
The construction of a true artificial nose is an enormous undertaking. The assembly of thousands of different proteins onto a chip is not meant to be presented lightly. But also in analogy to electronics, biosensors have often been paced or measured by sensor density, whether that’s in an affinity array or in next-generation sequencing. I argue the same scaling applies here – perhaps the peanut sensor can be constructed from a very small subset of the total receptors expressed, if all you’re interested in is sensing peanuts, and then you could grow applications as you learned how to pack more and more channels onto the device.
Other major technical risks involve the potential for multi-participant interactions in one bound state. On paper, such data structures exist to model this behavior (hypergraphs). I don’t know how much such higher-order structures contribute to cell signaling or olfaction, but if it is important, the scale of the problem may increase by several orders of magnitude – the space of potential interactions would grow exponentially. Another major technical hurdle is in sensor diversity – if, rather than a few thousand, post-translational modification or complexation results in the generation of many orders of magnitude more kinds of receptors which are important for olfaction, then the problem isn’t really able to be tackled piecemeal (a few thousand dollars per protein expression doesn’t scale to millions of proteoforms well).
The author is an employee of Nautilus Biotechnology, briefly mentioned in the material above. The opinions expressed in this essay are the author’s alone, and were not reviewed or endorsed by Nautilus Biotechnology or any of its affiliates.
References
[1] https://www.jstor.org/stable/2369436?origin=crossref&seq=2
[2] https://www.youtube.com/live/AKMuA_TVz3A?si=5SJscOvWfJRu-LGm
[3] https://www.nature.com/articles/s41598-023-31612-w
[4] https://www.nature.com/articles/s41467-023-36736-1
[5] An olfactory connectome has been published for Drosophila https://elifesciences.org/articles/66018
[6] https://www.nature.com/articles/nbt1388
[7] Many toxins follow a “permanent smell’ schema – they’re toxic because they bind to a receptor and never let go or otherwise damage it in the binding process, and can’t be metabolized effectively. These fixed endpoints are common failure modes for metabolism.
[8] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10394212/
[9] https://pubmed.ncbi.nlm.nih.gov/24042236
[10] https://www.sciencedirect.com/science/article/abs/pii/S2468170918300195
[11] https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4539275
[12] https://cgejournal.biomedcentral.com/articles/10.1186/s40575-022-00116-7 It is not clear how many proteoforms contribute to scent, which is a limitation of the current known architecture.
[13] https://www.scientificamerican.com/article/medicine-nobel-awarded-fo/
[14] https://earth.org/carbon-offset-schemes/
[15] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8775878
This is an award-winning entry for the Ideas Writing Challenge